Use Training Sets in a Module
Much like how the process of creating and configuring a training set is specific to your use case, how you choose to incorporate a training set in a module workflow is largely dependent on your business problem and what your specific needs are. However, there are some common use cases where training sets, and especially text extraction training sets, are very powerful.
One common use case is leveraging training sets to extract text from files in PDF format and using that text somewhere else in a workflow. To understand how a training set is often implemented in this way, let's look at an example use case in some detail.
Example Use Case and Walkthrough
In the Finance and Accounting department, we receive invoices for all the purchases made by employees, all of which come from our sole contractor, the Fourth Dimension Corporation. Employees drop these invoices into a designated Google Drive folder. Each invoice is in PDF format and features a machine-generated filename that makes it difficult to easily determine the content of the invoice, causing problems for our team. Here's an example invoice, titled "invoice_71331389_billing_dept_march_2022":

Today, our team needs to open each invoice to confirm the information and then rename the file with the employee name, the invoice number, and the exact date for later processing—a time-consuming and expensive process.
This is an ideal use case for training sets, which allow us to automatically identify and extract the information we need from the invoice. We can then use various actions in the module builder to rename the file whenever an invoice is added to the Google Drive folder, effectively automating what now takes one person hours each week to do.
Create and Configure the Training Set
Before we begin building the module, the first step is to create the necessary training set.
To extract the data we need from the invoice, we create a text extractor-type training set, "Rename Invoices," which includes an extraction model for each field we need to rename the invoice:
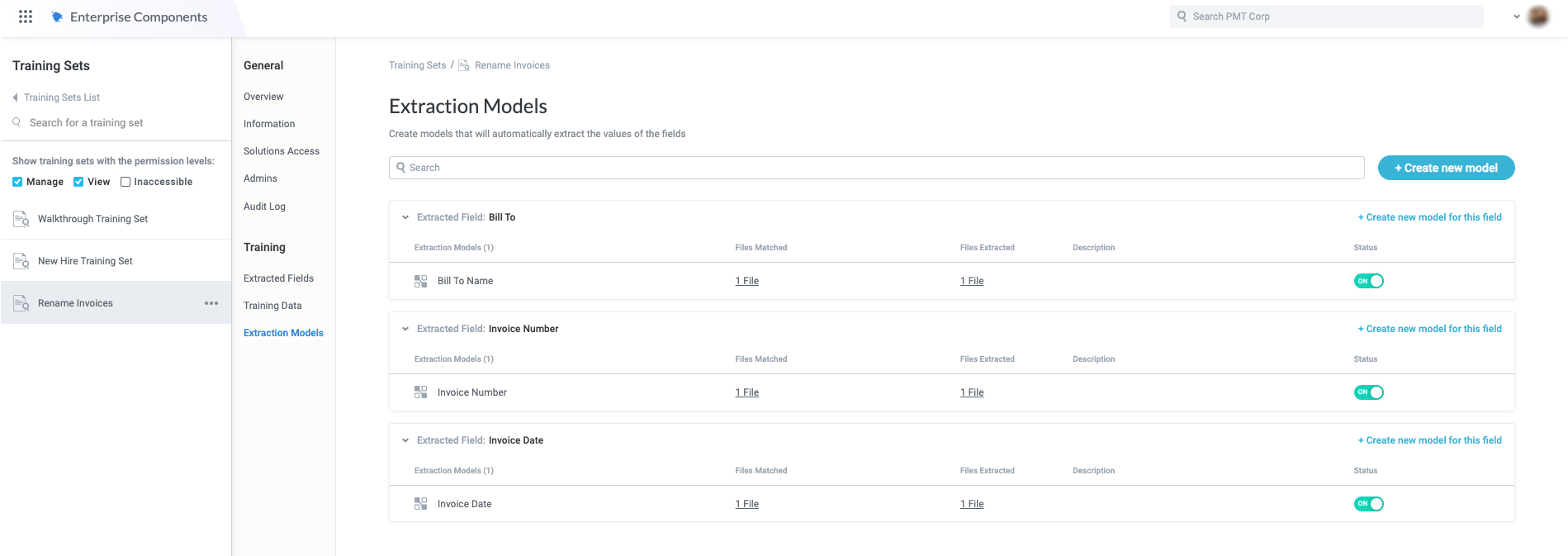
Because the invoices all have identical formatting, we only need to maintain one extraction model for each field. If we expected different formats in the invoices, we would create an extraction model for each field variant to ensure we don't miss any values.
Following the procedure for configuring a training set, we upload the above PDF and tag the appropriate fields, ensuring the extraction models successfully locate and extract the text we need. Notice in the extraction model configuration window for the Bill To field that the target text is highlighted and we see a Success indicator in the upper right:
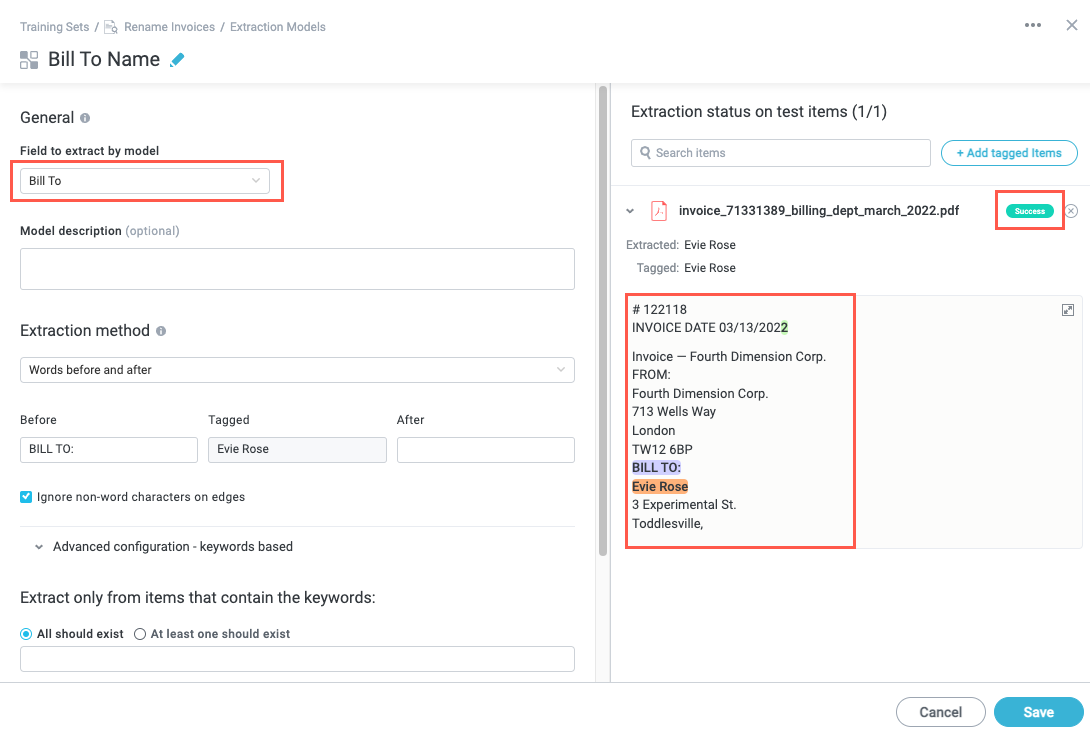
Now that we've established what information we need and have created a training set to locate and extract that information, we're ready to leverage the training set in our module.
Build the Module Workflow
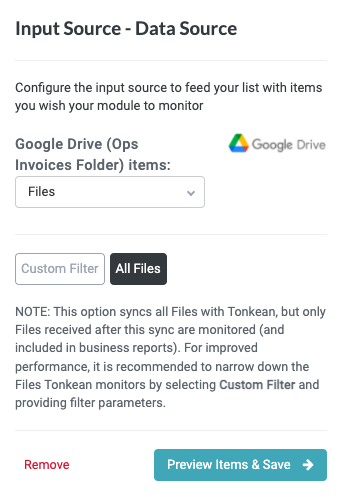
First, we must give the module access to the invoice PDFs our employees add to our Google Drive folder. The most direct way to do this is to connect that Google Drive folder as a native cloud application data source.
We configure the data source to monitor All Files because we know that only invoices are added to the folder. If other files were regularly added to this folder, we would create a filter that only monitored the files we care about.
Our module is now monitoring the Google Drive folder and is automatically configured to run each time a file is added, so we must now build the logic to extract the fields we need and rename the file.
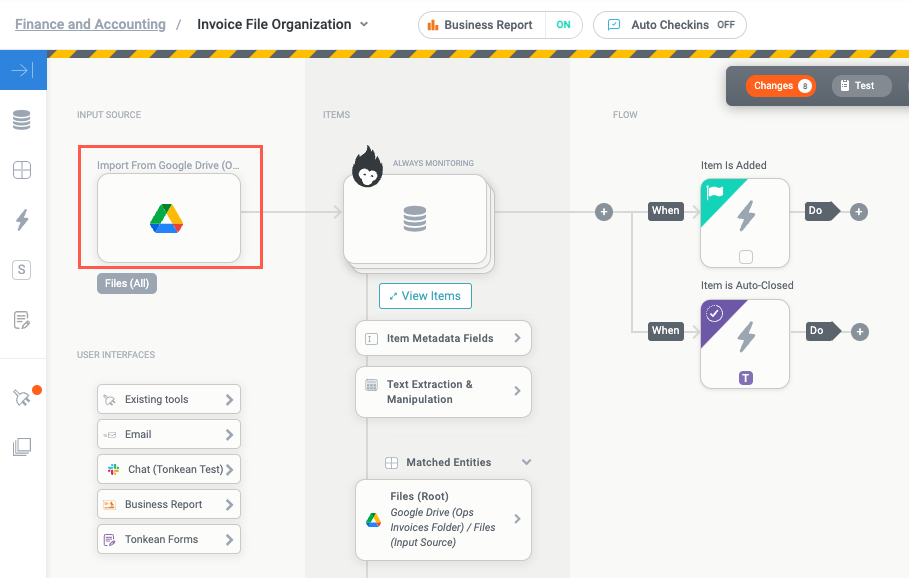
Our training set cannot extract text directly from a PDF, so the first action we need after the Item is Added trigger is the OCR Conversion action, which converts either PDF or TIFF files to text.
We add the OCR Conversion action and select the Google Drive data source we connected as the Data Storage option. This specifies where to locate the file we want the module to perform OCR conversion on. Additionally, we specify that we want to perform the conversion on the Root Monitored Item, which is the PDF file itself.
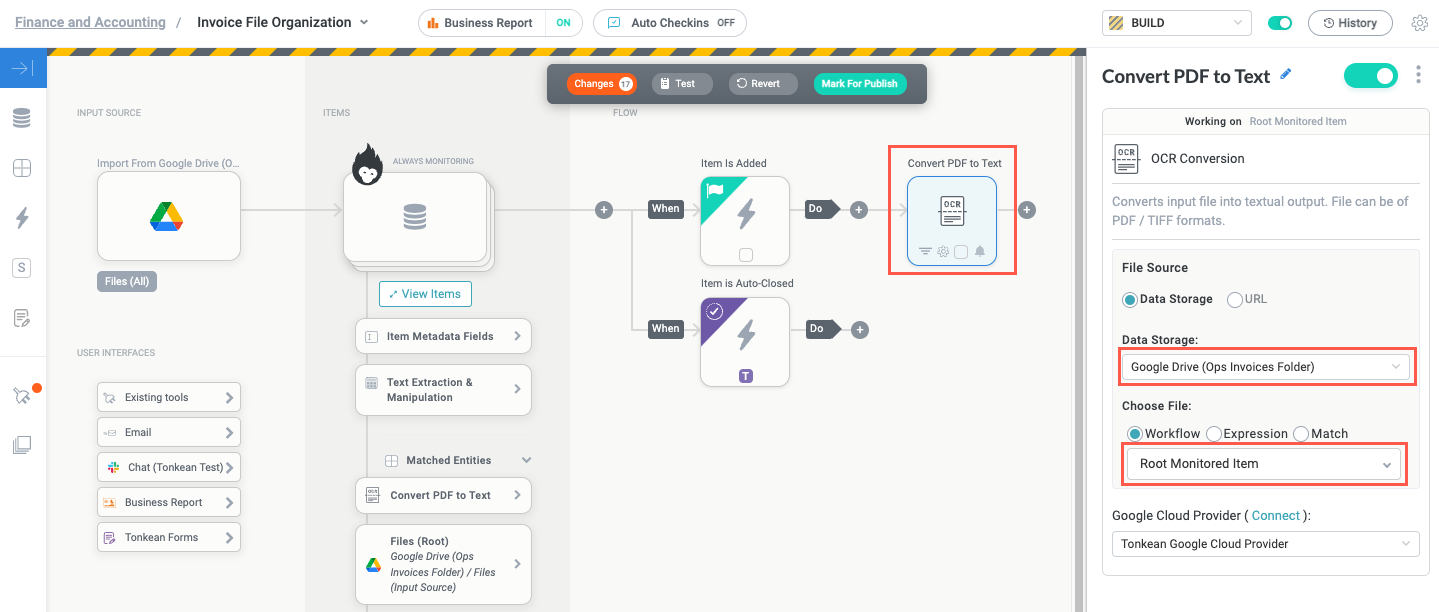
After adding the OCR Conversion action and configuring the Data Storage and Choose File fields, Tonkean automatically creates a new matched entity field that contains the extracted text. The OCR Conversion Text extracted field contains the text the OCR Conversion action generated from the PDF.
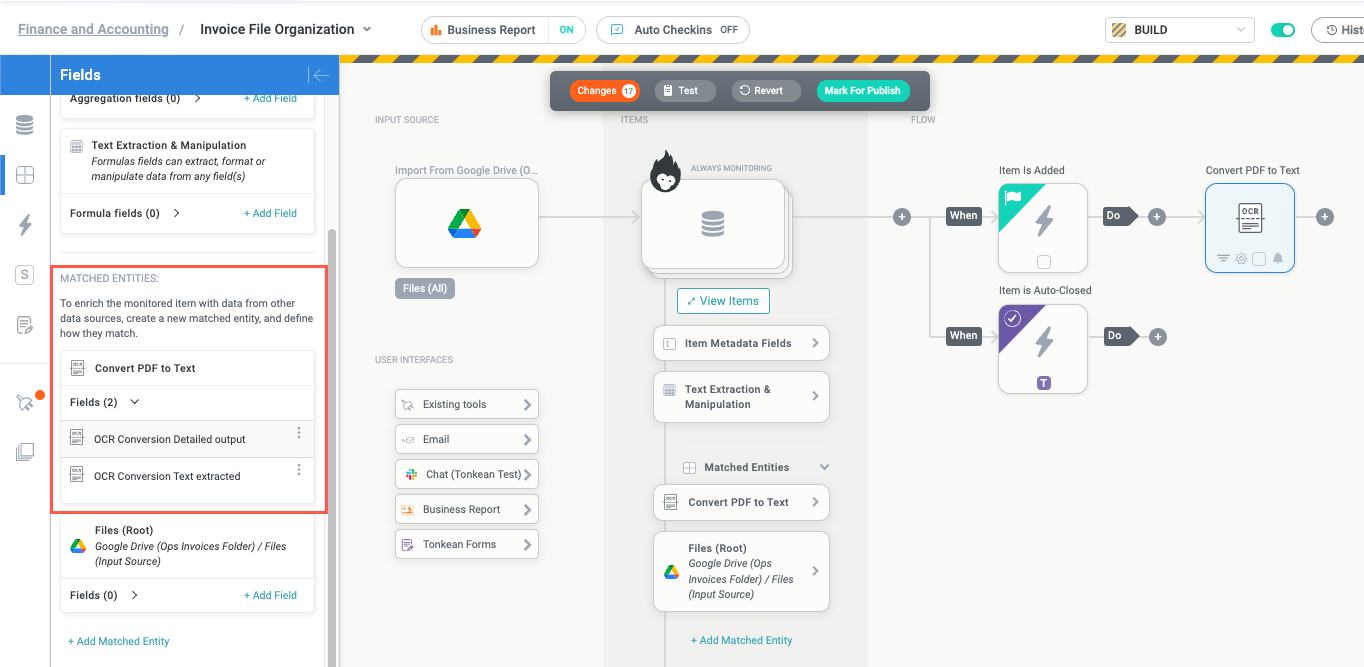
We now have a field, OCR Conversion Text extracted, where the PDF's extracted text is stored, so we can now add a Text Extractor action block to leverage the training set we created earlier.
In the same way we added the OCR Conversion action, we add a new Text Extractor action block, give it a unique name for our workflow, and then configure it:
In the Input field, we select the insert field button,
 , and select OCR Conversion Text extracted. This is the text from the OCR conversion we want the training set to process.
, and select OCR Conversion Text extracted. This is the text from the OCR conversion we want the training set to process.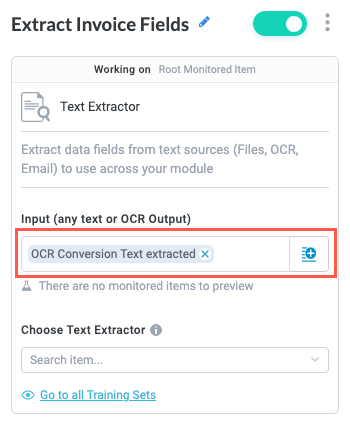
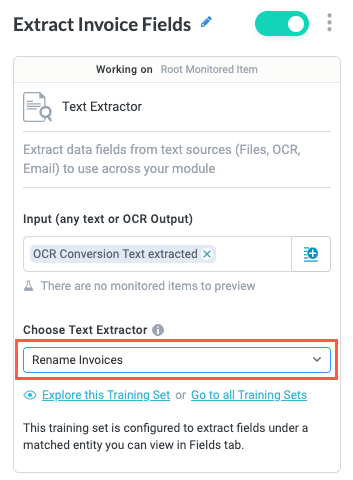
In the Choose Text Extractor field, we select the dropdown and choose the training set we created, Rename Invoices.
In the same way Tonkean automatically creates fields for the OCR conversion output, it creates a matched entity with fields for the training set extraction models:
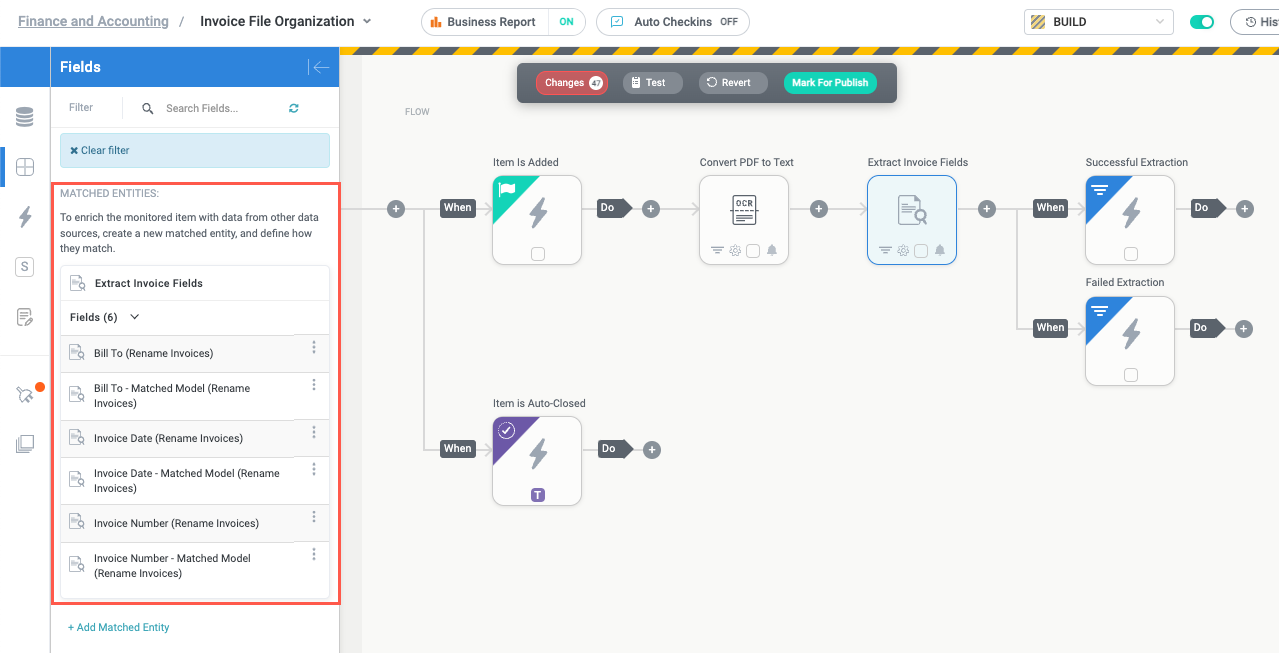
By default, there are two fields created for each value extracted by a training set: the field value itself and the model used to extract the field. For example, in the above image, there are two fields for the Bill To field in our training set: Bill To (Rename Invoices), which is the value extracted by the training set, and Bill To - Matched Model (Rename Invoices), which is the name of the model that successfully extracted the value. In most cases, you only need the first field containing the extracted value, but there are some situations where knowing the extraction model used is helpful, such as when you want to initiate a different workflow if a particular extraction model is used.
At this point in the workflow, we have the logic that converts the invoice PDF to text and extracts the three fields we created in our "Rename Invoices" training set. In other words, we have the information we need to rename the file. Now, we need add the action to rename the file.
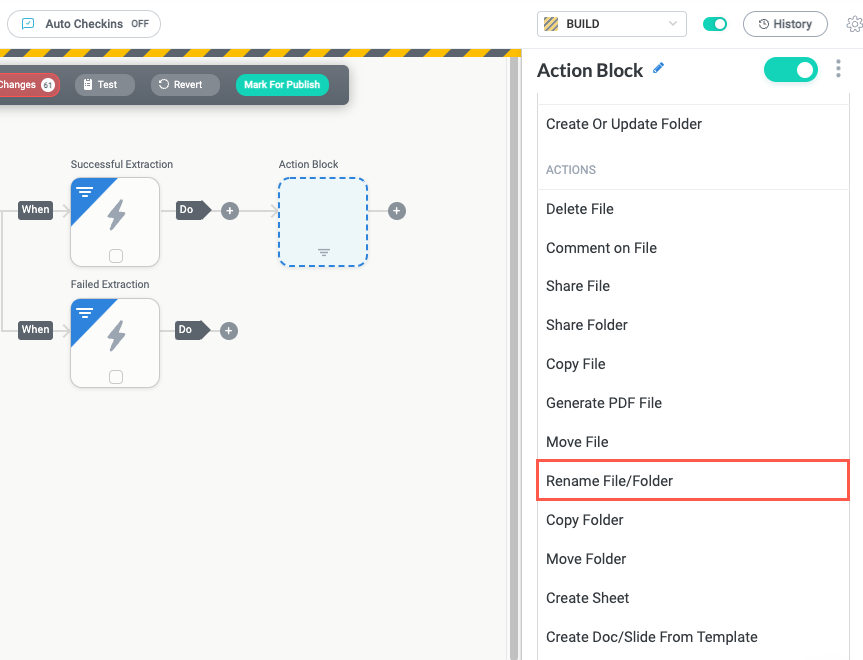
To rename the file that has successfully passed through our training set, we add a Google Drive data action, which includes a variety of application-specific actions like deleting the file, sharing the file, or, for our purposes, renaming the file or folder:
After the Successful Extraction trigger block, we add a Google Drive data action block. In the Action Block panel, we scroll down to ACTIONS and select Rename File/Folder.
In the New File/Folder Name field, we select the insert field button,
, and use the extracted fields from our training set to rename the invoice PDF.If we want to hard-code a name that shared by all invoices in the folder, we can add free text in this field. For example, if we want to add "Invoice", we could do that here.
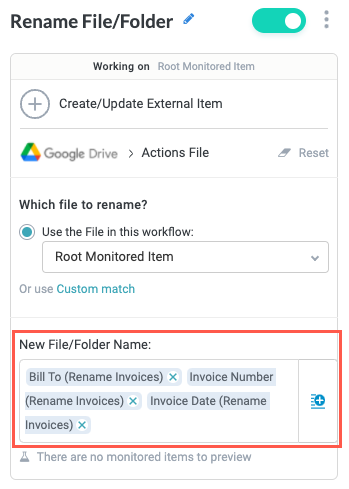
Remember to add spaces between fields if you want spaces in the filename. There are no spaces automatically added between inserted fields.
The logic for the branch where text extraction is successful is complete, but it's a best practice to include a workflow for when text extraction fails for whatever reason. Next, we build that logic.
Because our use case is fairly simple, we don't need a complex workflow for the Failed Extraction branch. We add a Train action that sends the failed text to our training set as a training example and then add a Send Notification action to tell a designated person they need to visit the training set and tag the new example to create a new model.
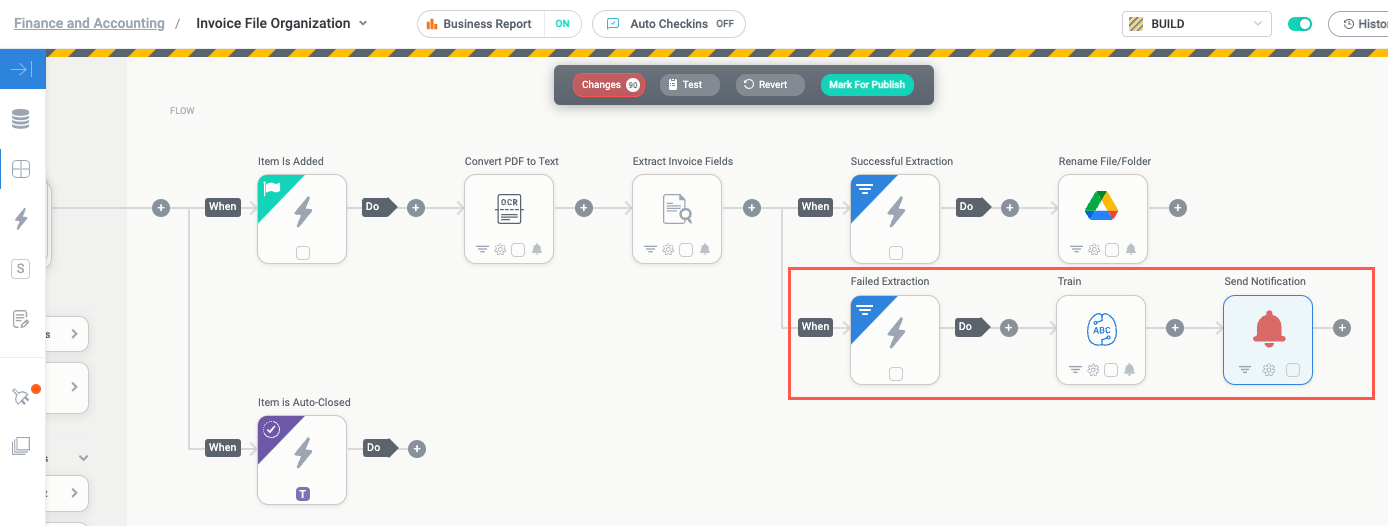
Sometimes, small variations in file format can cause the training set to fail, so building this re-train logic into the module makes creating new models a built-in part of the process.
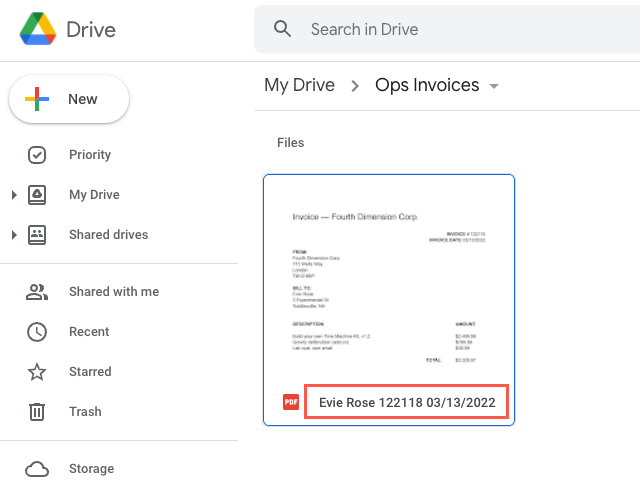
After testing and publishing, our module is complete. We open up our Google Drive folder and see the example invoice, previously named "invoice_71331389_billing_dept_march_2022" is renamed "Evie Rose 122118 03/13/2022", which is built from the three fields we extracted and specified as the values to replace the original filename.
With minimal logic, we have automated a previously time and labor-intensive process!
This example use case, while relatively simple, represents a common business problem. There are many repetitive tasks requiring extracting a few basic pieces of information that can easily be automated using training sets—and that automation can be just a small part of a larger workflow.
As with any other solution, we encourage you to test frequently and continue iterating on your workflow. Often, small refinements can add up to significant differences and potentially large process improvements.